Bit Function Benchmarks
Note
🤔 This is not an exhaustive benchmark suite, nor is it representative of all machines or architectures. All numbers should be taken in the context of the reported environment and standard library below, as well as any additional caveats listed.
The below benchmarks are done on a machine with the following relevant compiler and architecture details:
Compiler: Clang 13.0.0 x86_64-pc-windows-msvc
Standard Library: Microsoft Visual C++ Standard Library, Visual Studio 2022 (Version 17.0)
Operating System: Windows 10 64-bit
CPU: Intel Core i7: 8 X 2592 MHz CPUs
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 6144 KiB (x1)
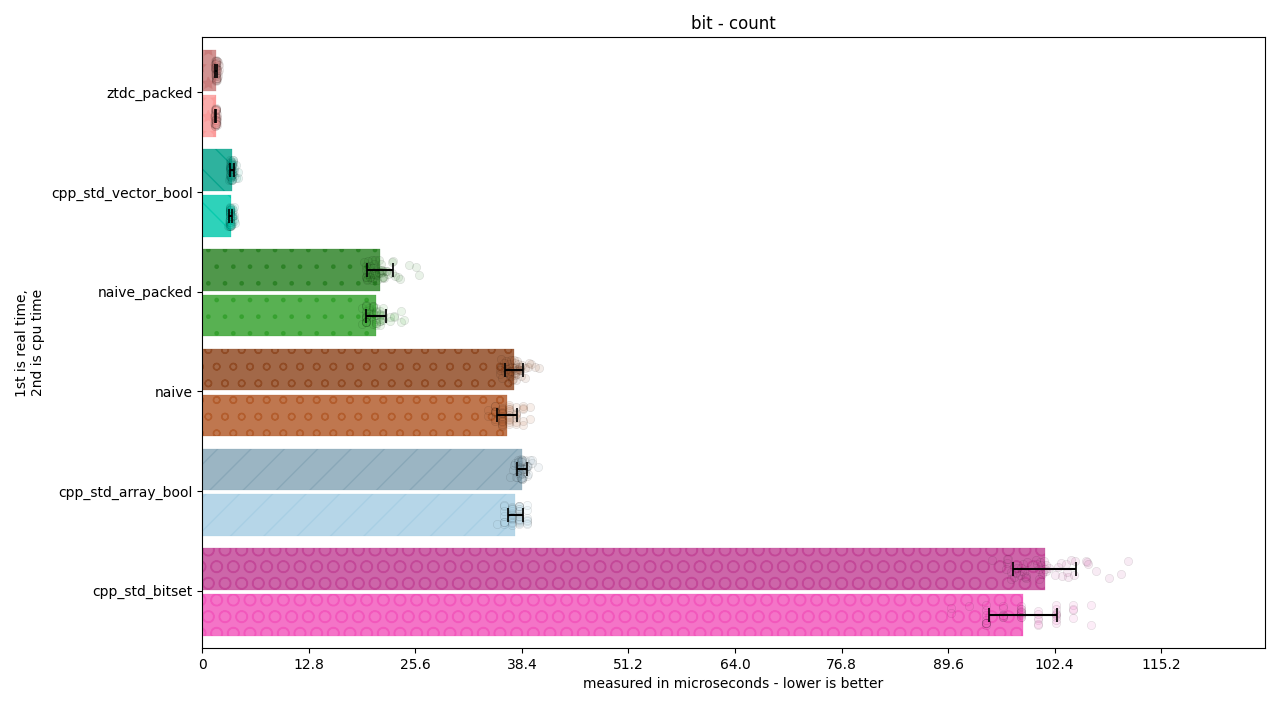
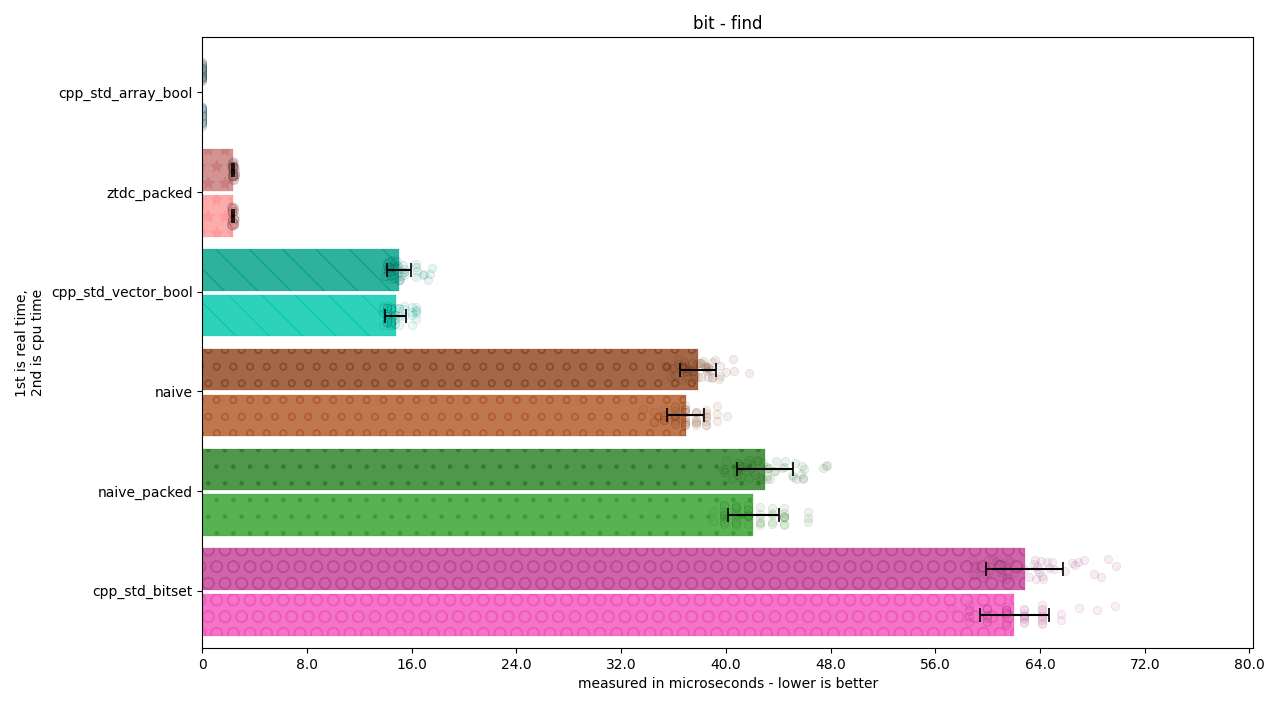
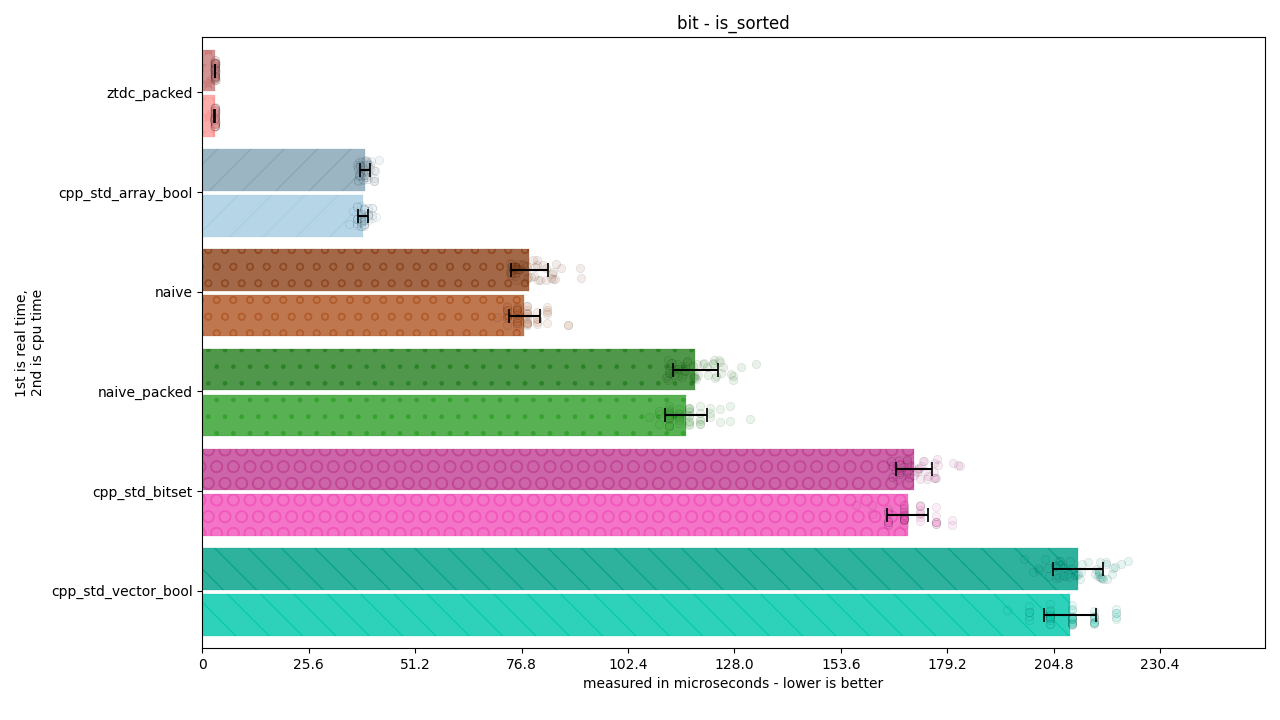
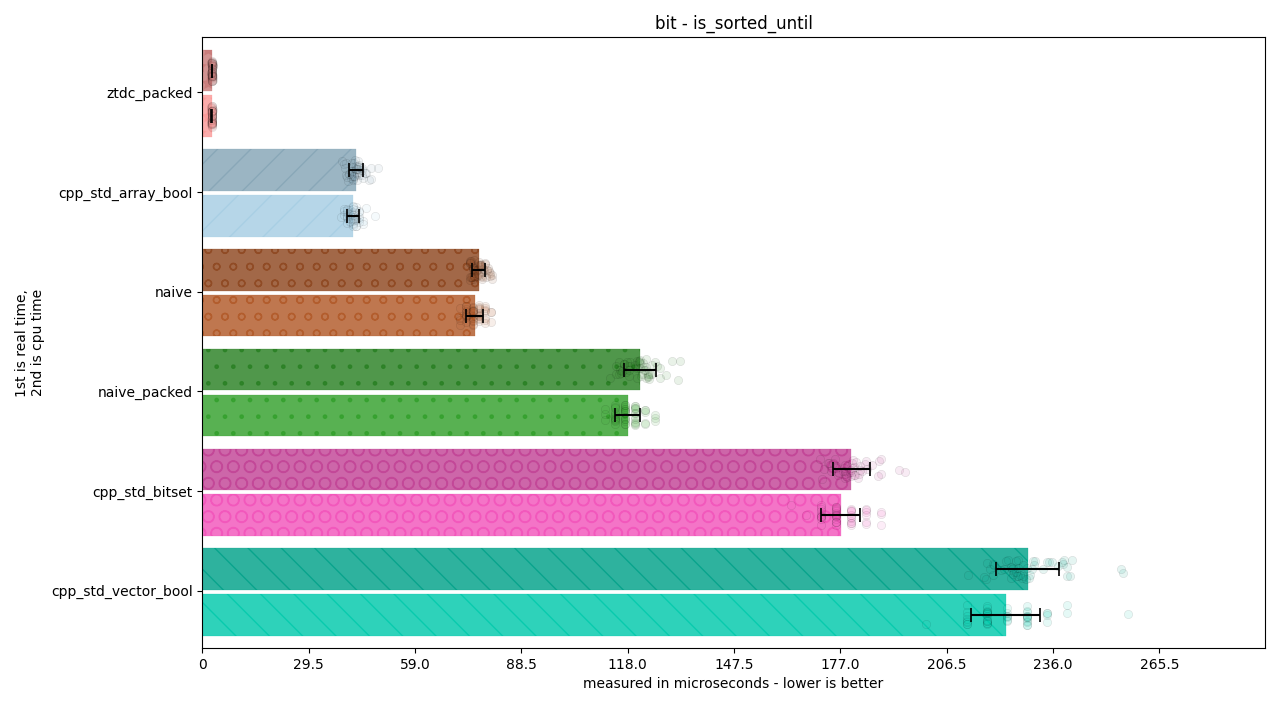
There are 4 benchmarks, and about 7 kinds of categories for each. Each one represents a way of doing work being measured.
naive: Writing a loop over a
std::arrayofboolobjects.naive_packed: Writing a loop over a
std::arrayofstd::size_tobjects and using masking / OR / AND operations to achieve the desired effect.ztdc_packed (this library): Writing a loop over a
std::arrayofstd::size_tobjects and using bit operations to search for the bit.cpp_std_array_bool: Using the analogous
std::algorithm (such asstd::find) on astd::arrayofboolobjects.cpp_std_vector_bool: Using the analogous
std::algorithm (such asstd::find) on astd::vector<bool>, or one of its custom methods to perform the desired operation.cpp_std_bitset: Using the analogous
std::algorithm (such asstd::find) on astd::bitset<...>or one of its custom methods to perform the desired operation.
Each individual bar on the graph includes an error bar demonstrating the standard deviation of that measurement. The transparent circles around each bar display individual samples, so the spread can be accurately seen. Each sample can have anything from ten thousand to a million iterations in it, and for these graphs there’s 50 samples, resulting in anywhere from hundreds of thousands to tens of millions of iterations.
Details
As of December 5th, 2021, many standard libraries (including the one tested) use 32-bit integers for their bitset and vector<bool> implementations. This means that, or many of these, we can beat out their implementations (even if they employ the exact same bit manipulation operations we do) by virtue of using larger integer types.
For example, we are faster for the count operation despite Michael Schellenberger Costa optimizing MSVC’s std::vector<bool> iterators in conjunction with its count operation, simply because we work on 64-bit integers (and roughly, the graph shows us as twice as fast).
Note
This is a consequence of having a permanently fixed ABI for standard library types, meaning that even if theoretically MSVC could be faster, a person can always beat out the standard library every single time if that standard library has long-lasting ABI compatibility requirements.
There are further optimizations that can be done in quite a few algorithms when comparisons are involved. For example, std::find can be implemented in terms of memchr for pointers to fundamental types: this is what makes the “find” for cpp_std_array_bool so fast compared to even the bit-intrinsic-improved ztdc_packed.
Note
Therefore, despite the last note, standard libraries still perform more optimizations than what a regular user or librarian can do! The Standard Library is not all depressing. 😁
Benchmarks